为了在有限的资源上学习大数据处理与分析技术,借鉴Linux以及部分网上的教程,在Windows10平台搭建Spark环境。本文将简单记录搭建流程以及其中遇到的坑。
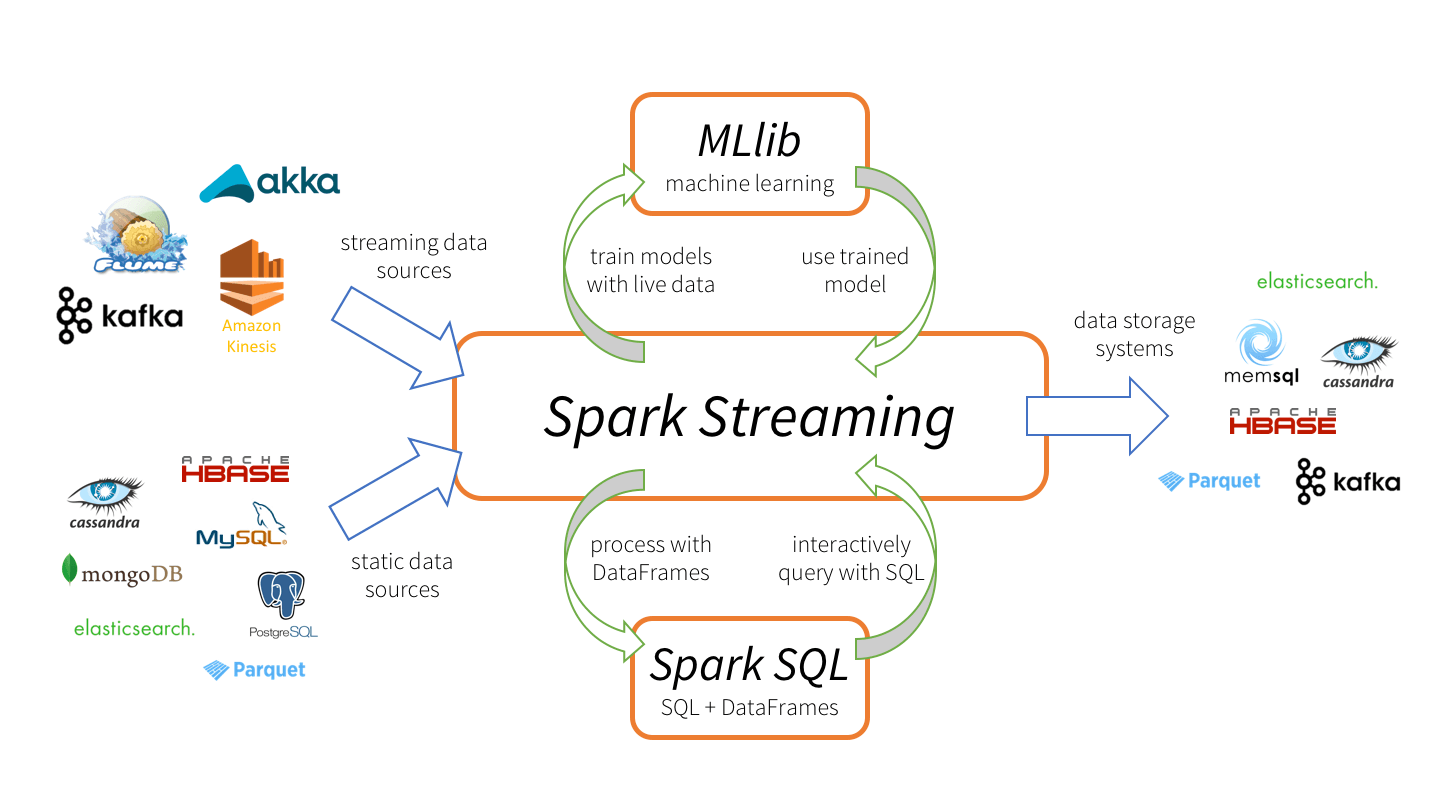
Spark的部署模式主要有四种:
- Local模式(单机模式)
- Standalone模式(使用Spark自带的简单集群管理器)
- YARN模式(使用YARN作为集群管理器)
- Mesos模式(使用Mesos作为集群管理器)
安装Java
- 到 Oracle Java 官网下载JDK并安装,安装路径建议直接选择
C:\Java,不要安装在Program Files中(路径有空格会导致后面配置Hadoop比较麻烦)- 添加环境变量
JAVA_HOME,值为安装路径,如C:\Java\jdk1.8.0_121 - 在环境变量
Path中增加值:%JAVA_HOME%\bin - 打开命令行测试是否安装成功,输入
java -version,应该出现如下信息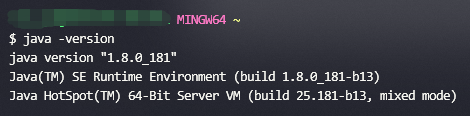
- 添加环境变量
安装Spark
到 Apache Spark 官网下载预编译的压缩文件,解压到某个路径中不含空格的文件夹下,也就成为Spark的安装路径,如
D:\spark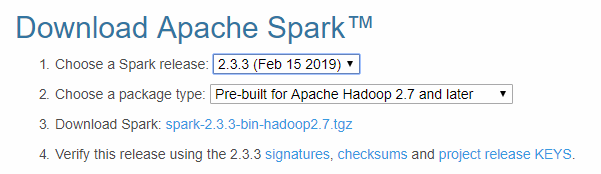
- 添加环境变量
SPARK_HOME,值为安装路径,如D:\spark - 在环境变量
Path中增加值:%SPARK_HOME%\bin和%SPARK_HOME%\sbin - 如果下载的Spark版本
>=2.3,建议进一步添加环境变量SPARK_LOCAL_HOSTNAME,值为localhost 进入Spark的配置目录
conf,复制一个log4j.properties.template文件并命名为log4j.properties,打开log4j.properties文件,进行如下修改# log4j.rootCategory=INFO, console
log4j.rootCategory=WARN, console同样在Spark的配置目录
conf,复制一个spark-env.sh.template文件并命名为spark-env.sh,打开并增加以下一行代码SPARK_LOCAL_IP = 127.0.0.1
- 添加环境变量
安装Hadoop
到 Apache Hadoop 官网下载预编译的压缩包(这里为了更好对应,选择下载2.7版本),解压到某个路径中不含空格的文件夹下,也就称为Hadoop的安装路径,如
D:\hadoop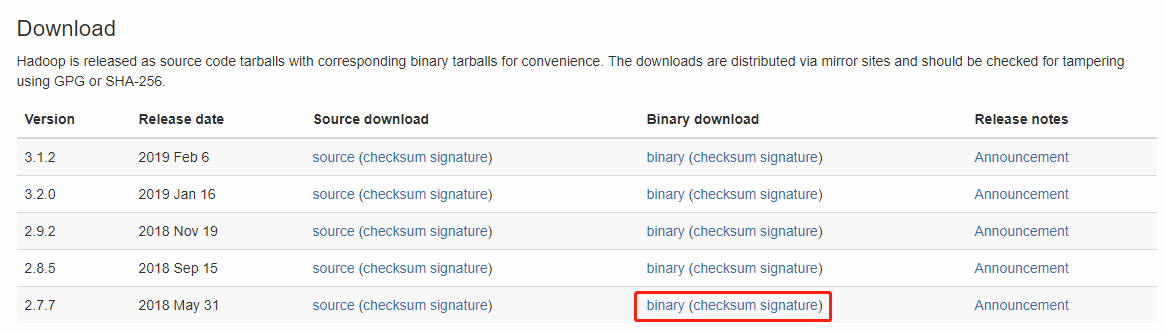
- 添加环境变量
HADOOP_HOME,值为安装路径,如D:\hadoop - 在环境变量
Path中增加值:%HADOOP_HOME%\bin和%HADOOP_HOME%\sbin 进入Hadoop的配置目录
etc\hadoop,打开文件hadoop-env.cmd,修改Java的安装路径,如果Java安装在Program Files可以通过设置为PROGRA~1解决空格报错的问题set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_121
下载对应版本的 winutils,把下载到的
bin文件夹覆盖到Hadoop安装目录的bin文件夹,确保其中含有winutils.exe文件新建
tmp\hive文件夹,如C:\tmp\hive,命令行导航到Hadoop的bin目录,执行以下授权操作winutils.exe chmod -R 777 C:\tmp\hive
最后在命令行输入
hadoop version测试是否安装成功
- 添加环境变量
验证Spark安装成功
- 打开命令行,运行
spark-shell,应该输入如下内容
- 此时进入
localhost:4040可以看到Spark的Web界面
使用Spark开发第一个程序
Python
安装PySpark
- 把Spark安装路径下的
python\pyspark文件夹复制到系统Python的包文件夹下,例如在Anaconda环境中,复制到D:\Anaconda3\Lib\site-packages目录下 - 安装Python包
py4j,在命令行运行pip install py4j - 验证PySpark配置成功,在命令行输入
pyspark,应该输出如下内容
在PyCharm中使用PySpark
下面以一个经典的词频统计(Word Count)程序为例,学习PySpark的使用,词频统计是一个很经典的分布式程序,这里用到中文分词库jieba,去除停用词再进行计数
- 新建Python工程,并新建脚本
wordcount.py - 在网上随便找一篇新闻报道,复制内容到文本文件
news.txt,记住其路径 - 到GitHub上搜索中文停用词资源,如从 https://github.com/stopwords-iso/stopwords-zh/blob/master/stopwords-zh.txt 下载得到
stopwords-zh.txt - 打开脚本并输入如下代码
# -*- coding: utf-8 -*- |
设置程序运行配置,打开
Run->Edit Configuration,按照如下图所示内容新建一个配置,其中环境变量必须加入SPARK_HOME、HADOOP_HOME以及SPARK_LOCAL_HOSTNAME
运行程序,最后输出前100个高频词语

程序提交到Spark运行
上述词频统计代码也可以直接提交到Spark运行,方法如下:
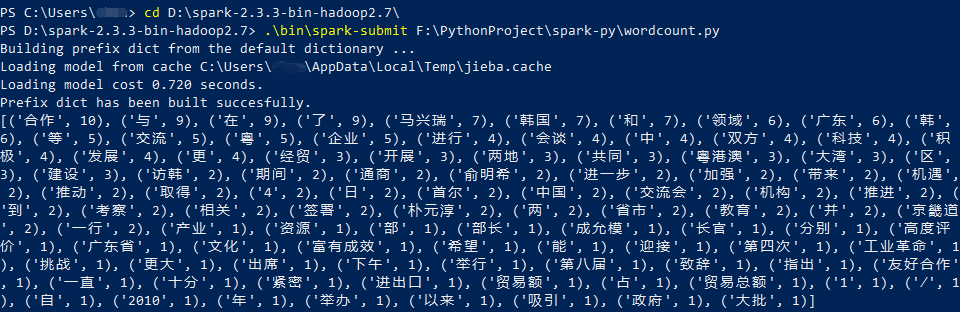
打开命令行,导航到Spark的安装目录,执行提交任务命令:
cd D:/spark
./bin/spark-submit /path/to/wordcount.py最后输出类似的执行结果
Scala & Java
Java
- 在 IntelliJ IDEA 新建一个Maven工程
在项目的Maven配置文件
pom.xml中加入Spark-core依赖,根据安装的Spark版本到 Maven Repository 仓库找到对应的Maven依赖文本,如:<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.3</version>
</dependency>打开工程目录下的主程序文件,通常为
./src/main/java/App.java,编写词频统计代码- 下面将以两种形式进行编写,Java Lambda的代码风格接近Python,易于阅读;而Java原生模式则稍显复杂
Java Lambda
import org.apache.spark.SparkConf; |
- 最后打开输出结果文件夹的
part-00000文件,输出各个单词的统计数:(Spark,7)
(and,7)
(the,5)
(Apache,5)
(of,4)
(for,3)
...
Java 原生模式
import org.apache.spark.SparkConf; |
- 最后结果与上面情况类似
Scala
(待更新)